parallel blasts using python's pp module
BLAST handles utilizes multiple cores for some scenarios using the -a flag. however, i often do full genome blasts -- blasting all chromosomes of one organism against all others. For the case of rice (O.s.) against itself, this is 124 jobs. there are simple tools in python to run a queued blast in which on my 8 core machine, each core will run 1 of those blasts, as a job finishes, the pp or parallel python module starts the next job, based on the number of cpus it has detected for your machine.
the syntax for the script is:
where rice_rice_10kmers is the section in a config/.ini file to get the parameters.
My fasta directory looks like:
the script will create (144 - repeats ) output files with names that look like:
The code below is what does the work:
which reads this config file:
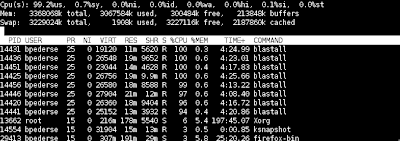
This will run a blast of all rice chromosomes (split into 10,000mers) against all other 10,000 mers. This is what top looks like on my 8-core machine.
the syntax for the script is:
python pblast.py rice_rice_10kmers
where rice_rice_10kmers is the section in a config/.ini file to get the parameters.
My fasta directory looks like:
$ ls /tmp/rice/fasta/
ricetenkmers_chr01.fasta ricetenkmers_chr04.fasta ricetenkmers_chr07.fasta ricetenkmers_chr10.fasta ricetenkmers.order
ricetenkmers_chr02.fasta ricetenkmers_chr05.fasta ricetenkmers_chr08.fasta ricetenkmers_chr11.fasta
ricetenkmers_chr03.fasta ricetenkmers_chr06.fasta ricetenkmers_chr09.fasta ricetenkmers_chr12.fasta
the script will create (144 - repeats ) output files with names that look like:
ricetenkmers_chr06_vs_ricetenkmers_chr09.blast
The code below is what does the work:
"""
this will parallelize the blast on a directory of fasta files. keeps
the number of CPUs on the given machine full until all jobs are done.
"""
import commands
import os
import sys
import pp
import glob
import ConfigParser
filen = lambda fullpath: fullpath[fullpath.rfind("/") + 1:fullpath.rfind(".")]
"""
>>> filen = lambda path: fullpath[path.rfind("/") + 1:path.rfind(".")]
>>> filen("/tmp/rice/fasta/ricetenkmers_chr06.fasta")
'/ricetenkmers_chr06'
"""
def gen_command(q_fastas, s_fastas, format_db, blast, out_dir):
"""
generator of blast commands given arguments:
'q_fastas' : a list/iterable of strings indicating the full path
to the set of query fastas.
's_fastas' : a list/iterable of strings ... subject ...
'format_db': a formatdb command (see pblast.ini for example)
'blast' : a blast command string (see pblast.ini)
'out_dir' : directory to write the blast output files
yields the full blast commands.
"""
for q_fasta in q_fastas:
q_name = filen(q_fasta)
for s_fasta in s_fastas:
s_name = filen(s_fasta)
out_name = os.path.join(out_dir, "%s_vs_%s.blast" % (q_name, s_name))
if not os.path.exists("%s.nin" % s_fasta):
print >>sys.stderr, "formatting %s" % s_fasta
# formatting db is not parallelized here ...
commands.getoutput(format_db % s_fasta)
# tell it where to send the output.
command = (blast % (q_fasta, s_fasta)) + " -o " + out_name
yield command
def consume(command):
return command, commands.getoutput(command)
def save_blast_info(out_dir, fomatdb, blast):
""" keep a record of the blast and format_db params used"""
bp = open(os.path.join(out_dir, "00blast.params"), "w")
print >> bp, format_db
print >> bp, blast
bp.close()
def main(q_fastas, s_fastas, format_db, blast, out_dir):
# create the server.
s = pp.Server()
if not os.path.exists(out_dir): os.makedirs(out_dir)
save_blast_info(out_dir, format_db, blast)
jobs = [] # this will hold all the pp jobs.
for c in gen_command(q_fastas, s_fastas, format_db, blast, out_dir):
# tell pp that we'll call the consume function
# (c,) is the argument list, where c is a string for hte blast
# command
# ("commands",) is a tuple of modules that will be needed for the job
jobs.append(s.submit(consume, (c,), (), ("commands",)))
# loop through and collect the jobs and any output as they return
for j in jobs:
command, output = j()
print command
if output: print output
if __name__ == "__main__":
config = ConfigParser.ConfigParser()
config.read("pblast.ini")
params = dict(config.items(sys.argv[1]))
format_db = params.get("format_db", "/usr/bin/format_db -p F -i %s")
blast = params.get("blast", "/usr/bin/blastall -p blastn -K 80 -i %s -d %s -e 0.001 -m 8 ")
query = params.get("query_files")
subject = params.get("subject_files")
out_dir = os.path.join(params.get("out_dir", "/tmp") , sys.argv[1].strip())
fasta_list = {"q": [], "s": []}
patterns = ("fa", "fasta", "faa", "fas")
for qs, fileset in (("q", query), ("s", subject)):
# it's either a directory, in which case get all fasta files.
if os.path.isdir(fileset):
for pat in patterns:
fasta_list[qs].extend(glob.glob(os.path.join(fileset, "*." + pat)))
# or it's a glob pattern
else:
fasta_list[qs] = glob.glob(fileset)
assert len(fasta_list[qs]) > 0, "didn't find any files for %s" % fileset
main(fasta_list["q"], fasta_list["s"], format_db, blast, out_dir)
which reads this config file:
[rice_rice_10kmers]
# is it protein? leave the %s to be filled programmatically
format_db=/usr/bin/formatdb -p F -i %s
# just use correct path and use all parameters here:
# the %s's get filled with query and subject files programmatically.
# the output file is chosen and appended programmatically.
blast=/usr/bin/blastall -p blastn -K 80 -i %s -d %s -e 0.001 -m 8
# where to send the blast output becomes:
# /tmp/rice_rice_10kmers/
out_dir=/tmp/
# a glob pattern or a directory
query_files=/tmp/rice/fasta/
# it's a self-self blast. so query and subject are same.
subject_files=/tmp/rice/fasta/
This will run a blast of all rice chromosomes (split into 10,000mers) against all other 10,000 mers. This is what top looks like on my 8-core machine.

Comments